北大数字人文中心两篇长文被LREC-COLING 2024录用
2024年3月20日
#
近日,北京大学数字人文中心博士生唐雪梅和段思宇分别作为第一作者的文章“CHisIEC: An Information Extraction Corpus for Ancient Chinese History”和“Restoring Ancient Ideograph: A Multimodal Multitask Neural Network Approach” 被自然语言处理高水平国际会议LREC-COLING 2024作为 Full paper 录用。前者发布了一个中国古代历史文献信息抽取数据集,后者探索了基于多模态多任务神经网络的古代表意文字修复方法。
本次会议由计算语言学领域的两大国际重要组织--欧洲语言资源协会 (ELRA) 和国际计算语言学委员会 (ICCL) 联合组织。国际计算语言学大会 (International Conference on Computational Linguistics,COLING) 是自然语言处理和计算语言学领域的重要国际学术会议,1965年开始举行,现每两年召开一次。在2022年发布的《中国计算机学会推荐国际学术会议和期刊目录》中,COLING会议被认定为CCF B类会议,在自然语言处理、人工智能领域具有重要的国际影响力。
值得注意的是,本次会议将Digital Humanities(数字人文)作为一个专门的track征稿,向自然语言处理技术与人文的交叉研究抛出橄榄枝,这反映了数字人文学科日渐扩大的影响力。会议将于2024年5月20-25日在意大利都灵举行,让我们在这里先一睹为快吧!
# 1. CHisIEC: An Information Extraction Corpus for Ancient Chinese History
#
CHisIEC: 一个中国古代历史文献信息抽取数据集
作者:唐雪梅、邓泽琨、苏祺、王军、杨浩
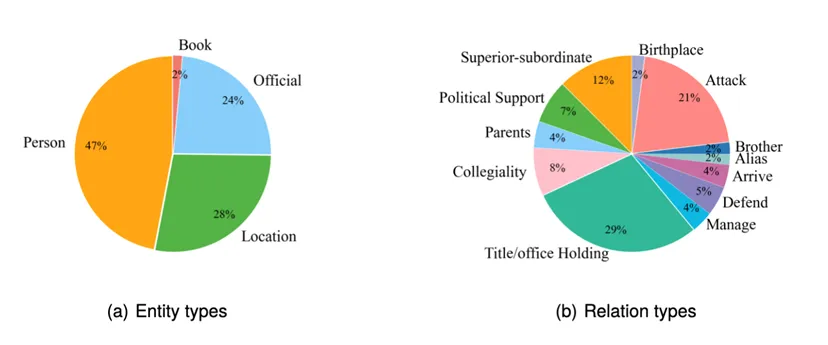
摘要: 自然语言处理(NLP)在数字人文(DH)领域发挥着重要的作用,是推进历史和文化遗产文本结构化分析的基石。为了促进古代历史和文化的发展,本文推出了 "中国历史信息提取语料库"(CHisIEC)。CHisIEC 是一个精心策划的数据集,旨在开发和评估 NER 和 RE 任务。CHisIEC 的历史时间跨度长达 1830 年,涵盖 13 个朝代的数据,是中国历史文献中时间跨度大、文本异质性强的缩影。该数据集包含四种不同的实体类型和十二种关系类型,形成了一个由 14,194 个实体和 9,056 个关系组成的数据集。为了验证数据集,本文设计了不同规模和范式模型的全面实验。
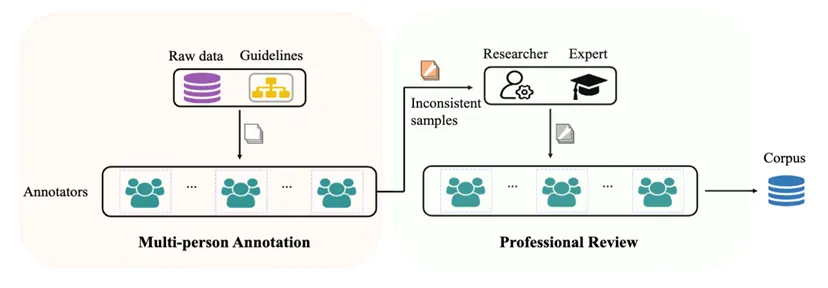
标注机制: 在大规模数据标注的实践中,采用了 "多人标注"(MP)和 "专业评审"(PR)的模式,18名大学生分成六组独立标注相同文本,不一致之处后由专家校对。
#
**数据集:**数据集统计信息如图所示。共标注 14,194 个实体和 9,056 条关系。
# 验证实验
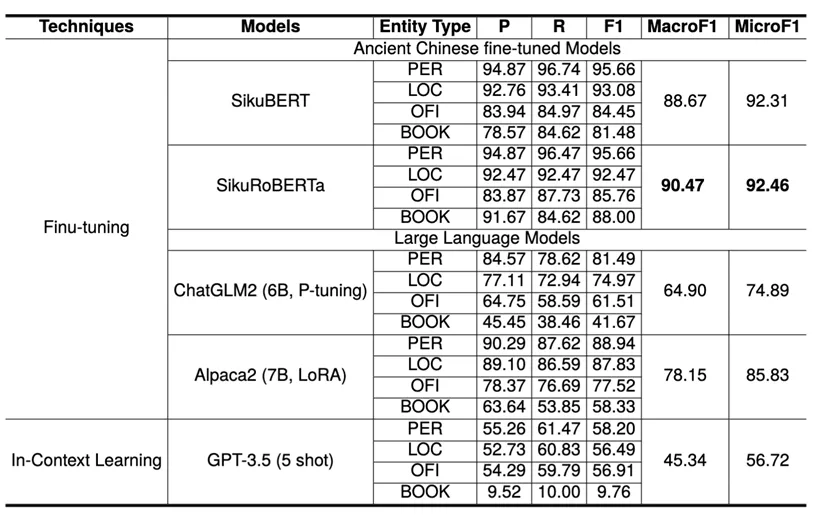
NER实验: 首先,NER结果表明预训练语言模型(PLMs)在性能上优于大型语言模型(LLMs)。此外,结果显示GPT-3.5在只用五个示例的情况下表现出令人期待的结果,说明了该模型在NER框架中的潜在能力。
#
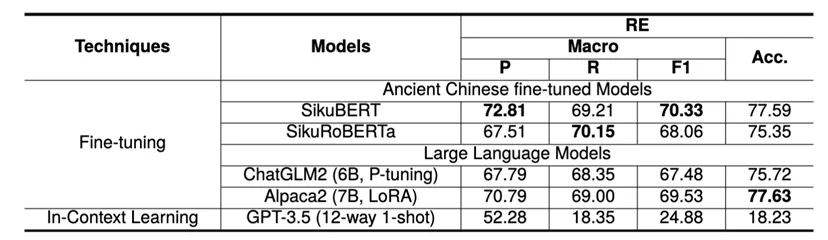
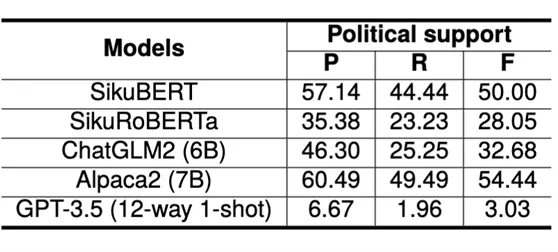
RE实验: ChatGLM2和Alpaca2的RE性能与PLMs相当。至于GPT-3.5,提供的样本数量有限似乎限制了其将关系类型限定为预定义集合的能力,导致生成了不在集合内的关系类型,从而降低了召回率。值得注意的是,所有模型在一个特定的关系类型上表现相对较差:Political Support,结果见下表。推测原因是该关系类型的语义复杂性,其语义包括 “支持”、“推荐”和“援救” 等。这使得模型难以总结与这种特定关系相关的特征。
#
# 结语
资源建设是实现古籍智能化的基础和前提。北京大学数字人文研究中心一直致力于在这一领域做出积极的贡献。本次中心通过建立共享数据的方式,推动了中国历史文献领域信息抽取任务的发展。诚挚地欢迎同行使用这些数据,并提供宝贵的反馈意见。数据将会在3月底公布,可以在github搜索CHisIEC获取。
# 2. Restoring Ancient Ideograph: A Multimodal Multitask Neural Network Approach
#
基于多模态多任务神经网络的古代表意文字修复方法
作者:段思宇,王军,苏祺
预印本:https://arxiv.org/abs/2403.06682 (opens new window)
摘要: 文化遗产是人类思想和历史的记录。尽管已经付出了大量努力来保护它们,许多古代文物仍然遭受了来自自然侵蚀和人类行为的损坏。在古代文本的修复方面,深度学习技术已经成为备受瞩目的方法。以往的研究主要从视觉或文本的角度进行,往往忽视了多模态信息协同的潜力。本文提出了一种新颖的多模态多任务修复模型(MMRM),用于修复古代表意文字。该模型结合了对受损古代文物的上下文理解与残留视觉信息,使其能够同时预测缺失字符并生成恢复的示意图。我们通过对模拟数据集和真实古代铭文进行的实验测试了MMRM模型。结果表明,所提出的方法在模拟实验和实际场景中都提供了可圈可点的修复建议。
**数据:**除了50万句古代中文语料,该项工作还利用了108种繁体字体来模拟受损文字的图像,从而指导多模态多任务训练。在真实场景验证方面,使用了《九成宫醴泉铭》的真实碑拓图像,和人文学者考证后的文字修复结果。
数据与代码均已公开发布:https://github.com/CissyDuan/MMRM (opens new window)

#
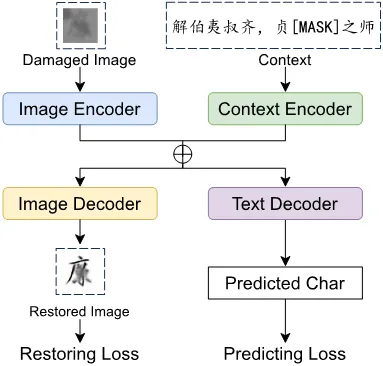
模型: 模型由图像编码器(Resnet50)、上下文编码器(RoBERTa)、图像解码器(反卷积)、文本解码器(MLP)四个模块组成,分别执行对图像和文本的编码和解码。训练目标有两个:预测受损的字符,以及恢复受损的图像。训练时,用逐渐增大受损面积的方法来进行课程学习。
#
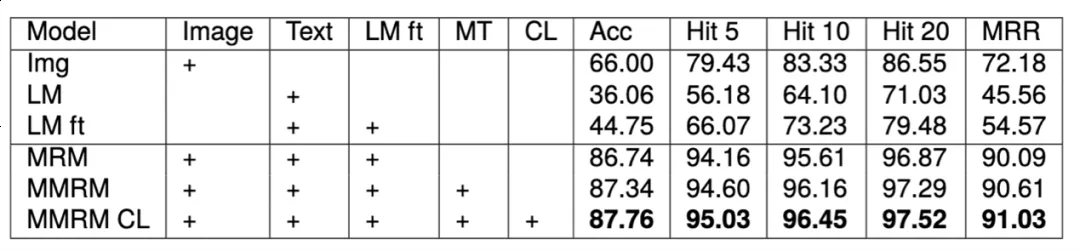
实验结果: 在模拟实验中,多模态方法比单纯使用图像和文本取得明显提升,多任务学习和课程学习能帮助模型进一步取得提升。
#
在随机丢失多个字符的场景,效果会有一定下降,但依然可以取得不错的效果。
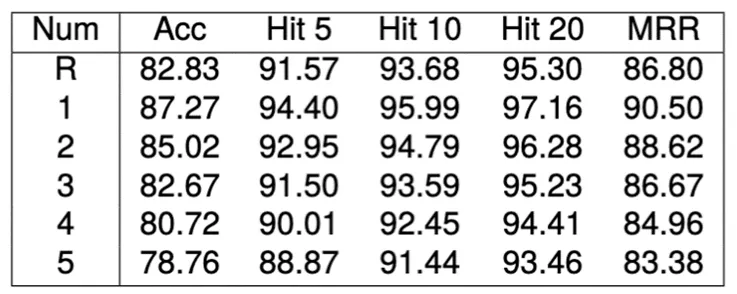
#
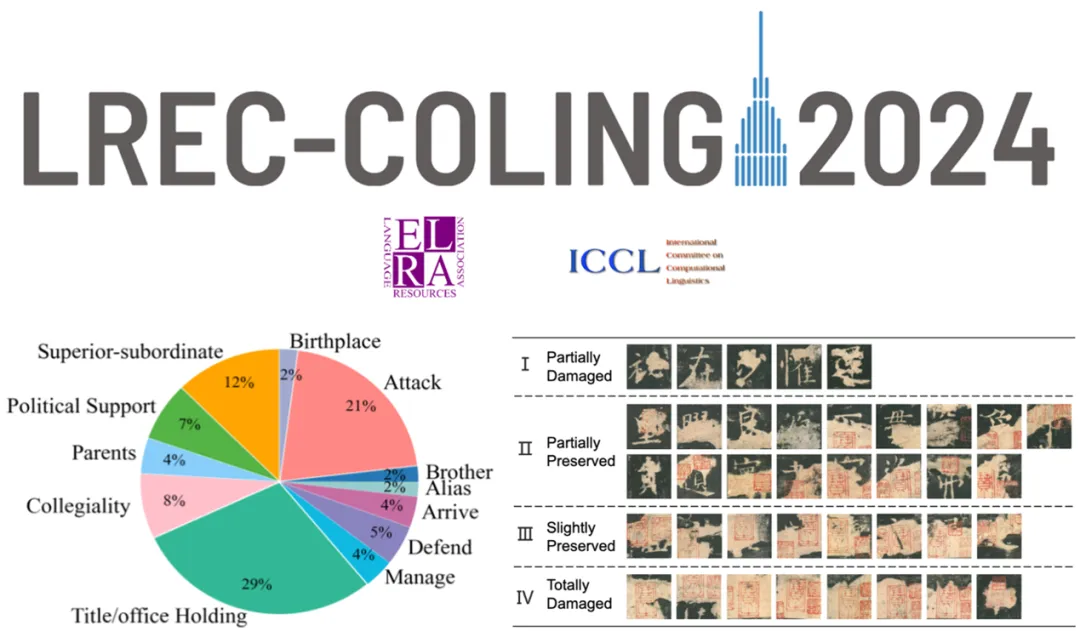
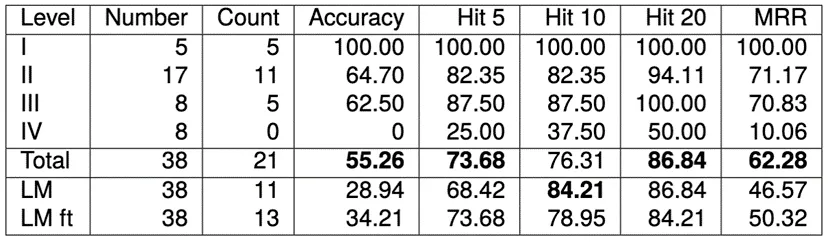
真实场景: 我们将《九成宫醴泉铭》中38个受损字符按受损程度分为四类,观察其修复效果。

#
可以看到,提出的多模态模型在真实场景中的大部分情况能取得比单纯使用上下文信息更好的效果。但在损坏等级IV,图像完全损坏的情况,直接使用语言模型效果更佳。
#
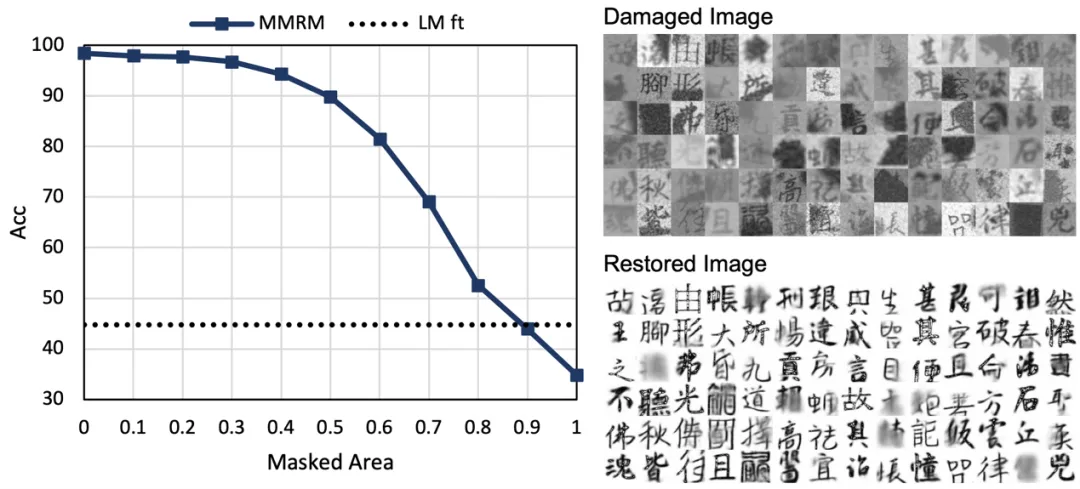
我们考察了不同损坏面积和修复准确度的关系,使用正方形遮罩来模拟。从左下图可以发现,当损坏正方形边长大于0.9倍文字图像边长时,多模态方法表现不佳。从右下图展示的损坏图像及其修复图像来看,当损坏面积过大时,模型不能生成有意义的结果。这是提出方法的局限性所在。
# 结语
这项工作综合利用了自然语言处理(NLP)和计算机视觉(CV)领域的方法,用于恢复古代文本文物。未来有许多潜在研究方向:如何检索和利用外部数据库中的参考信息来增强文本修复效果?如何利用深度学习方法来帮助识别低资源古代文字,比如3000年前的甲骨文?如何设计交互式的古代文本修复工具,为缺乏必要编程技能的人文学者服务?我们期待这项工作在学术和工业领域的应用。